Overview
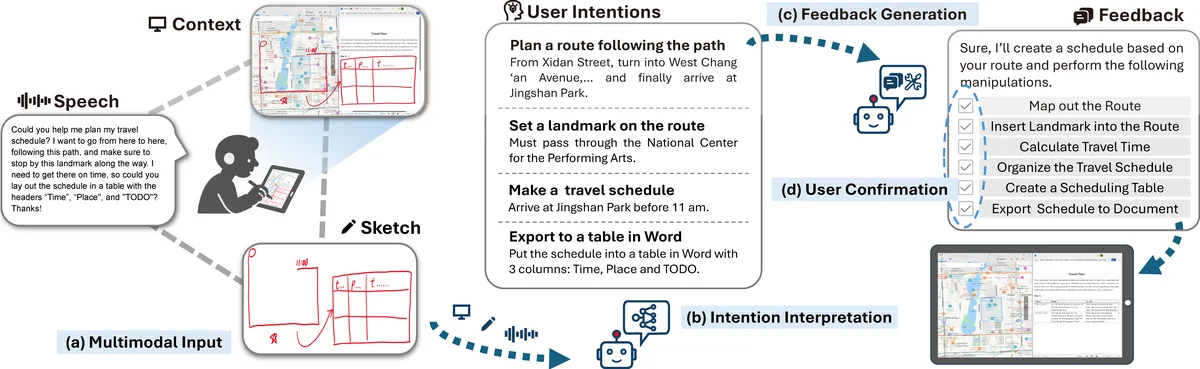
Human interaction with large language models (LLMs) is typically confined to text or image interfaces. Sketches offer a powerful medium for articulating creative ideas and user intentions, yet their potential remains underexplored. We propose SketchGPT, a novel interaction paradigm that integrates sketch and speech input directly over the system interface, facilitating open-ended, context-aware communication with LLMs. By leveraging the complementary strengths of multimodal inputs, expressions are enriched with semantic scope while maintaining efficiency. Interpreting user intentions across diverse contexts and modalities remains a key challenge. To address this, we developed a prototype based on a multi-agent framework that infers user intentions within context and generates executable context-sensitive and toolkit-aware feedback. Using Chain-of-Thought techniques for temporal and semantic alignment, the system understands multimodal intentions and performs operations following human-in-the-loop confirmation to ensure reliability. User studies demonstrate that SketchGPT significantly outperforms unimodal manipulation approaches, offering more intuitive and effective means to interact with LLMs.
@inproceedings{
title={SketchGPT: A Sketch-based Multimodal Interface for Application-Agnostic LLM Interaction},
author={Huang, Zeyuan and Gao, Cangjun and Shan, Yaxian and Hu, Haoxiang and Li, Qingkun and
Deng, Xiaoming and Ma, Cuixia and Lai, Yu-Kun and Liu, Yong-Jin and Tian, Feng and
Dai, Guozhong and Wang, Hongan},
booktitle={},
year={2024}
}